Intro
Data loss is not a possibility; its an eventuality and your backup strategy will determine whether its a minor inconvenience or a complete disaster.
We will discuss storage techniques like compression and deduplication backup types (Full, Differential and incremental) how they work together and retention policies.
But mainly this guide will walk you through the best practices you need and how to use backups techniques to create a great backup strategy.
Understanding Backup Techniques Basics – Backup Types
Backups come in different forms, each serving a distinct purpose in data protection. A well-designed backup strategy often combines multiple backup types to balance speed, storage efficiency, and recovery time.
Full Backup
A full backup creates a complete copy of all data, including every file and folder in the system. This is the foundation of any backup strategy.
When you perform a full backup, it captures everything, making it the simplest and fastest to restore because if something goes wrong, you can recover everything from a single backup without needing to piece together multiple backups.
However, full backups require significant storage space and time to create and that’s why they are usually performed less frequently while being supplemented by other backup types.
A common practice is to schedule full backups during off-peak hours when system resources aren’t strained to ensures minimal disruption to daily operations.

Differential Backup
A differential backup stores all changes made since the last full backup – unlike a full backup, which copies everything, a differential backup only captures what has changed.
For example, if a full backup is taken on Sunday and a differential backup is performed on Monday, it will contain only the new and modified files since Sunday and if another differential backup is taken on Tuesday, it will contain all changes since Sunday – not just changes made on Monday.
This method offers a balance between speed and restore efficiency since each differential backup grows in size as more changes accumulate and storage usage increases over time. However, restoring data is simpler than with incremental backups because you only need the latest full backup and the most recent differential backup.
Incremental Backup
Incremental backups take efficiency a step further by instead of storing all changes since the last full backup, an incremental backup only records changes made since the last backup whether it was full or incremental.
For instance, if a full backup is taken on Sunday:
- Monday’s incremental backup saves only Monday’s changes.
- Tuesday’s incremental backup saves only changes made since Monday.
- Wednesday’s backup captures only changes made since Tuesday.
Incremental backups are incredibly space-efficient, requiring minimal storage compared to full or differential backups and they also complete much faster since they only copy small amounts of data.
However, all of this backup efficiency comes with a cost when restoring from incremental backups as that can be very time-consuming because it requires assembling multiple backups in sequence from the last full backup and every incremental backup taken since then.
This method is ideal for environments requiring frequent backups with minimal impact on system performance.
Making Backups Efficient: Compression & Deduplication
Data Compression
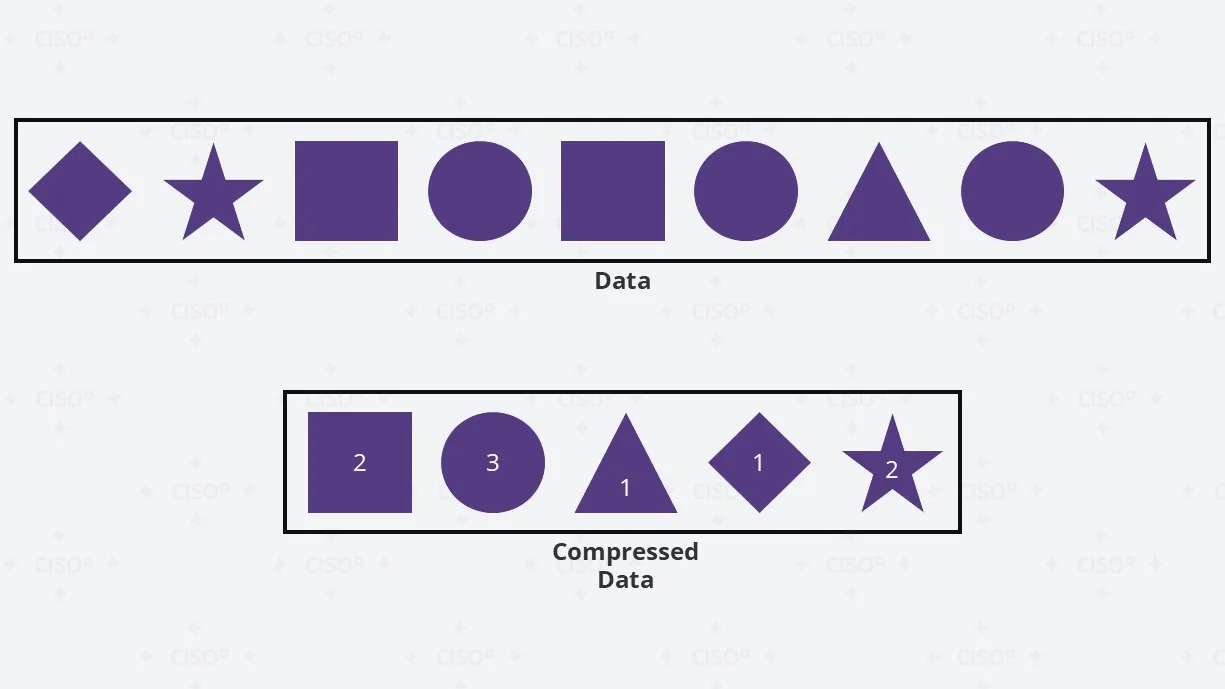
Data compression reduces the size of backups, saving storage space and improving transfer speeds which is why any modern backup solutions automatically compress data, but settings can be fine-tuned.
There are many different types and technics of compression but essentially compression (lossless compression in our case) reduces file size without losing any data, meaning the original content can be perfectly reconstructed. It works by identifying patterns and redundancies in data and representing them more efficiently.
The best example of that is something called Run-Length Encoding (RLE) which Works well with repetitive sequences by replacing consecutive duplicate values with a single value and a count. For instance, if the Original Data looks like this “AAAAAABBBBCCCCC” a Compressed RLE Data will look like this “6A4B5C” (6 times A + 4 times B + 5 times C).
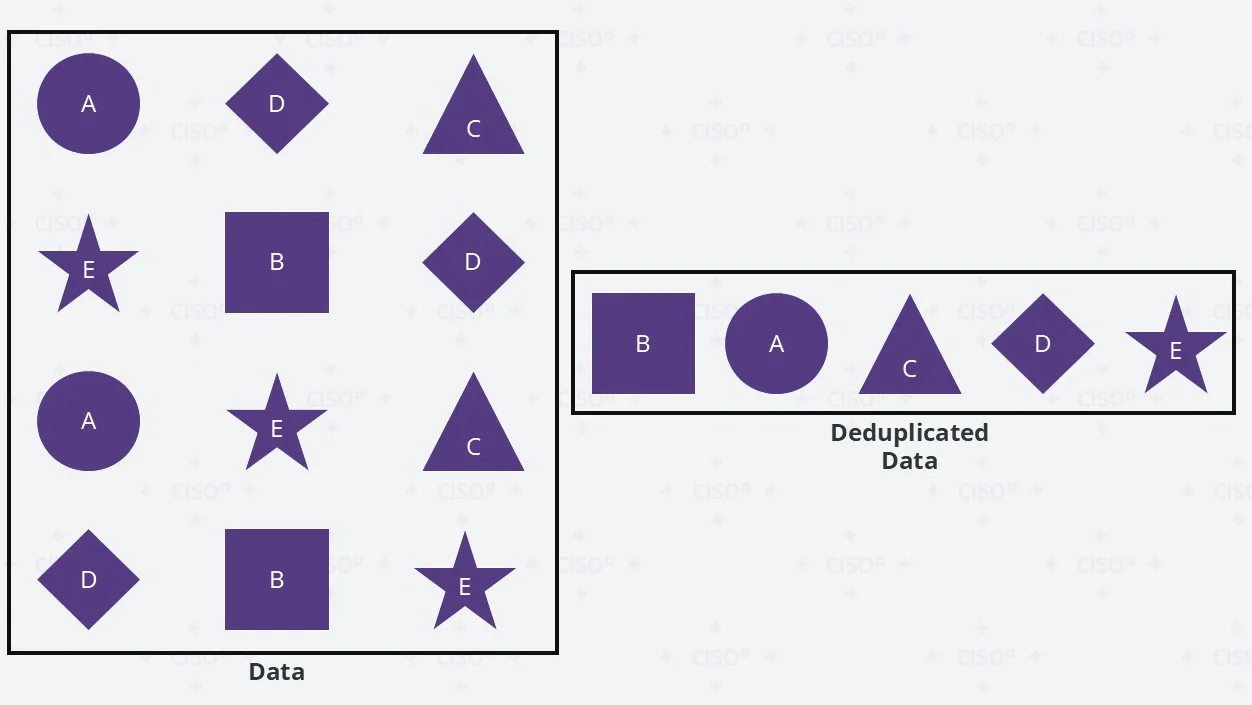
Data Deduplication
Deduplication eliminates redundant copies of data, keeping only unique instances. Instead of storing the same file 100 times across different backups, deduplication stores it once and references it where needed.
The deduplication process involves the following key steps:
- Chunking (Data Segmentation) – The data is divided into smaller segments (chunks).
- Hashing (Fingerprinting) – Each chunk is assigned a unique hash value and If two chunks produce the same hash, they are considered duplicates.
- Indexing (Metadata Storage) – A deduplication index keeps track of unique chunks and their locations and if a duplicate chunk is found, only a pointer is stored instead of the full data.
- Storage & Retrieval – When a file is written, only unique chunks are stored and when a file is read, its chunks are reconstructed using references.
Deduplication Methods
1. Block-Level Deduplication
This approach breaks data into fixed-size blocks, then compares their unique fingerprints to identify and remove duplicates. While highly precise, block-level deduplication can be resource-heavy and challenging to scale across large physical storage environments.
2. Variable-Length Deduplication
Instead of fixed-size blocks, this method uses algorithms to determine segment sizes dynamically, allowing for more efficient and flexible duplicate detection. It offers the same level of precision as block-level deduplication but adapts to varying data structures.
3. File-Level Deduplication
In this simpler method, entire files are compared to detect duplicates. While it lacks the fine-grained accuracy of block-level techniques, file-level deduplication is faster, less demanding on system resources, and easily applied to storage of any size.
Deduplication Points
1. Source Deduplication
Deduplication occurs on the client side before data is sent to the backup target. This reduces network usage and transmission costs but increases resource consumption on the client machine.
2. Target Deduplication
With this method, deduplication happens at the storage target after data transfer. It relieves the client of processing overhead but increases the demand on network bandwidth and the target’s resources.
Deduplication Timing
1. Inline Deduplication
Duplicates are identified and eliminated in real time as data is written or transferred. This saves storage space immediately but requires more processing power during the operation.
2. Post-Process Deduplication
Data is first written to the storage target, and deduplication occurs afterward. While this approach uses more storage up front, it reduces the processing load during data transfer.
Retention Policies – How Long Should You Keep Backups?
Retention policies dictate how long backups are stored before being deleted or archived. An effective retention strategy ensures that data remains available for recovery while balancing compliance requirements, storage limitations, and business continuity needs. Retention policies also help organizations optimize storage costs, prevent unnecessary data accumulation, and ensure that critical information is available when needed for audits, legal purposes, or recovery.
Key Factors in Determining Retention Periods
A well-designed retention policy should consider several key factors:
- Regulatory & Compliance Requirements – Industries such as healthcare, finance, and legal services often have strict retention requirements. For example, HIPAA mandates healthcare providers retain records for 6 years, while financial institutions may be required to store certain data for 5 to 7 years under SOX (Sarbanes-Oxley Act).
- Business Needs & Recovery Objectives – Organizations must balance short-term operational recovery needs with long-term historical record-keeping. A business may need quick access to recent backups but retain older copies for forensic analysis or compliance audits.
- Storage Capacity & Cost – Retaining large volumes of backups indefinitely can be cost-prohibitive, especially for cloud-based storage solutions. A tiered retention approach can help manage costs by storing recent backups on faster storage (e.g., SSDs) and older backups on archival storage (e.g., tape or cloud cold storage).
- Risk Management & Cybersecurity Considerations – Retention policies should account for potential ransomware attacks, accidental deletions, or insider threats, ensuring that backup copies exist beyond the reach of immediate threats (e.g., offline or air-gapped backups).
Common Backup Retention Strategies
Organizations use different retention strategies based on business needs and regulatory requirements. Here are some widely adopted models:
1. Grandfather-Father-Son (GFS) Retention Strategy
A structured approach that ensures multiple levels of backup availability over time:
- Daily (Son): Retain backups for the last 7 days
- Weekly (Father): Retain weekly backups for a month
- Monthly (Grandfather): Retain monthly backups for a year or longer
Use Case: Ideal for businesses that need a mix of short-term recovery and long-term archival storage while minimizing excessive storage costs.
2. 7-14-30 Rule
This strategy follows a simplified retention period:
- Daily backups for 7 days
- Weekly backups for 14 days
- Monthly backups for 30 days
Use Case: Suitable for businesses that require quick recovery within a short window but don’t need long-term archival storage.
3. Compliance-Based Retention
Certain industries require backups to be stored for extended periods due to legal or regulatory mandates. Examples include:
- HIPAA (Healthcare): Retention of electronic medical records (EMRs) for 6 years
- PCI-DSS (Payment Card Industry): Financial transaction logs retained for 1 year
- GDPR (General Data Protection Regulation): Data retention must align with the data minimization principle (organizations cannot keep backups longer than necessary)
- SOX (Sarbanes-Oxley Act): Financial records may need retention for 5 to 7 years
Backup Policy in Business Continuity & Disaster Recovery Planning
Backups play a crucial role in both Business Continuity Planning (BCP) and Disaster Recovery Planning (DRP) by ensuring that critical data remains available during disruptions and enabling rapid recovery from catastrophic failures. A well-defined backup policy is essential for minimizing downtime, preventing data loss, and maintaining operational resilience.
The Role of Backups in BCP & DRP
- Business Continuity Planning (BCP) – Backups help maintain the ongoing functionality of business operations by providing access to essential data, even in the event of partial system failures or localized incidents. The goal is to minimize disruptions and ensure that employees, customers, and stakeholders can continue to interact with business systems with minimal impact therefore, backup types used are important to allow at least some of the data to be restored quickly to allow business continuity.
- Disaster Recovery Planning (DRP) – Backups are a core component of disaster recovery, allowing organizations to restore operations after major incidents such as cyberattacks, natural disasters, or hardware failures. DRP focuses on the systematic restoration of data, applications, and infrastructure to resume business operations after an unexpected event which is why backup locations are critical and at least one backup storage must remain intact even in the case of disaster.
Creating a Good Backup Policy
A well-structured backup policy is essential to ensure business continuity and data resilience in the face of cyber threats, hardware failures, or accidental deletions. Developing a robust backup strategy involves multiple layers of planning, implementation, and continuous evaluation. Below is a detailed approach to building an effective backup policy:
Identifying Critical Data: Not all data holds the same level of importance, so the first step in creating a backup policy is classifying data based on its criticality to business operations.
- High-priority data: Includes customer records, financial data, databases, proprietary software, and other mission-critical assets.
- Moderate-priority data: Documents, project files, and email archives that may not be immediately essential but are still valuable.
- Low-priority data: Temporary files, cached data, and other non-essential information that does not require frequent backups.
By categorizing data appropriately, businesses can optimize storage space and backup frequencies.
Assessing Risks: Understanding potential threats helps in designing a resilient backup strategy.
- Cyber Threats: Ransomware and malware attacks that encrypt or corrupt data.
- Hardware Failures: Hard drive crashes, server malfunctions, and power failures.
- Human Errors: Accidental deletions, file overwrites, and configuration mistakes.
- Natural Disasters: Floods, fires, earthquakes, and other environmental risks that could impact data centers.
By conducting a risk assessment, businesses can prioritize backup solutions that mitigate the most pressing threats.
Selecting Storage Solutions: Choosing the right backup storage solution involves balancing security, accessibility, cost, and compliance requirements.
- On-Premises Storage: Provides full control over backups but requires infrastructure investment and maintenance.
- Cloud Storage: Ensures scalability, remote accessibility, and automated redundancy but depends on third-party providers.
- Hybrid Approach: Combines on-premises and cloud storage, ensuring local fast recovery with cloud-based disaster recovery.
Organizations must also consider compliance regulations such as GDPR, HIPAA, or PCI-DSS when selecting storage solutions.
Reviewing & Updating Policies: A backup policy is not a one-time effort—it requires continuous evaluation and adaptation to remain effective. Businesses should:
- Conduct Regular Audits: Evaluate the effectiveness of backup strategies and identify areas for improvement.
- Update Policies Based on Business Growth: As data volumes increase and operations expand, backup infrastructure should scale accordingly.
- Stay Ahead of Emerging Threats: Adapt security measures to address new cyber threats and vulnerabilities.
Key Recovery Metrics
Before creating your backup policy and defining backup frequency, you must understand the different recovery needs and Align backups with business objectives, ensuring that critical systems meet required targets. In other words, you need to answer the following questions:
- Recovery Time Objective (RTO): How long can systems be down before it severely impacts the business?
- Recovery Point Objective (RPO): What is the maximum acceptable data loss in terms of time (e.g., last hour, last day)?
- Maximum Tolerable Downtime (MTD): The longest period a system can be offline before causing irreversible harm.
- Weighted Risk Trend (WRT): A metric that evaluates and tracks risks over time based on their severity, likelihood, and potential impact.
An effective backup plan is tightly integrated with BCP and DRP, ensuring that recovery is not just possible but meets business requirements.
Creating a good backup strategy
Now that we understand the concepts, let’s talk about actual backup strategy in the real world.
Creating a great overall backup strategy requires a comprehensive and thoughtful approach that balances data protection, availability, cost-efficiency, compliance, and scalability. The first step is to identify and classify all types of data according to their importance — separating critical business data (like customer information, financial records, and databases) from less critical data (such as cached files or temporary data).
Once classified, establish backup frequencies tailored to each category, with mission-critical data backed up more frequently and less essential data on a more relaxed schedule.
A robust strategy should leverage multiple storage solutions, combining on-premises backups for fast recovery and cloud-based storage for offsite protection and disaster recovery.
This hybrid model ensures that even in the event of a major system failure or natural disaster, data remains safe and accessible. It’s also crucial to implement tiered retention policies, balancing short-term operational needs with long-term archiving requirements, while staying compliant with industry regulations like GDPR, HIPAA, or PCI-DSS.
Security is another pillar of a strong backup strategy — backups should be encrypted both in transit and at rest, with strict access controls and multi-factor authentication to prevent unauthorized access. Additionally, include offline or air-gapped backups as a safeguard against ransomware attacks and insider threats.
Regular testing and validation are essential; schedule periodic recovery drills to verify that data can be restored quickly and accurately when needed. Monitor backup jobs for errors and maintain detailed logs and reports for audit readiness.
Finally, your backup strategy should not be static. Continuously review and update it based on changes in business operations, data growth, emerging cybersecurity threats, and new technologies. Engage stakeholders from IT, compliance, and business leadership in regular strategy reviews to ensure alignment with evolving business continuity goals. By following these steps, you can build a resilient, cost-effective, and future-proof backup strategy that supports long-term business stability and peace of mind.
Tips:
- Use the 3-2-1 Rule: Three copies of data, two different storage types, one offsite backup.
- Automate Everything: Manual backups fail due to forgetfulness and human error.
- Test Restores Regularly: A backup is worthless if you can’t restore it.
- Secure Backups: Encrypt backups to prevent unauthorized access.
- Monitor and Alert: Set up alerts for failed backups so issues don’t go unnoticed.
Wrap Up
A great backup strategy isn’t just about having copies of your data – it’s about ensuring those copies are reliable, accessible, and secure.
Implement full, differential, and incremental backups strategically be sure to use compression and deduplication to optimize storage and establish a retention policy that balances cost with compliance. Most importantly test your backups regularly!
Your data is your business. Protect it like it matters. Because it does.

